
Versioning in general and a brief explanation of version types
So, first of all, let’s start with the understanding of why we need to version our code. Actually, there are two kinds of versions: internal and public (commercial or release versions).
The internal version is what developers see. It’s simply a tracking of each code change. And, fortunately, VCS (Git, SVN, etc.) does it for us. That’s why it is also often called “the revision." It allows us to refer changes in the task tracking systems, continuous integration systems (CI), and documentation. I’d call it a way to help organize your work.
The public version is what end-users see. It’s a way to show that something new was added to the software. It also helps distinguish software releases and attach a change log to them. The software name stays the same but there is a different version name, which is a way to show the users that they could update to a newer, better version (if they pay for it!). ;)
Just don't forget: some companies also use codenames for their products in addition to the previous version types - a sort of alias of the actual combination of name and version.
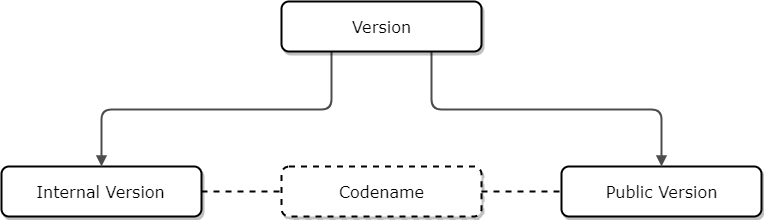
So, how does the version actually look like? Perhaps it is a silly question, and everyone who is familiar with the subject can give their own answer. But I’ll try to add something new, or at least, make a systematization.
The internal version looks different depending on what VCS is used:
SVN assigns a number for each code change and just increments it (e.g. 1, 2, 3, 4, 5…). This can be easily included into the public version! More about this later.
Git uses the SHA1 checksum of the change to mark it, e.g. 14d98eb6886be3392e262d744fa8cb665322b631.
The public version has a pretty standard format and it looks like this:
XX . XX . XX . XX
(At least the first two positions are used in most cases.)
However, the values of each position are different from project to project, and from company to company based on their own conventions. There are no strict standards for assigning the version values, but there are popular options and recommendations. I will mention only the ones which are most-often used.
In most cases, desktop applications use the following schema:
MAJOR . MINOR . BUILD . REVISION
The main idea is to reflect the significance of changes. MAJOR means that the application received some significant changes, including some big, new features. It is often something incompatible with the previous versions. MINOR could show that the developers have done some minor work, fixed something, etc. BUILD and REVISION are often generated automatically by CI during the release. More strict rules for this schema are described in Semantic Version Specification (http://semver.org). It is quite cool, but requires careful manual tracking and coordination with a product manager, who actually decides from the commercial point of view when and what should be released and how it should be reflected in the version.
Sometimes companies include another meaning of the version. For instance:
MAJOR . MINOR . MAJOR . MINOR
The first two positions are for a server-side version, the other two are for a client application version.
Or like JetBrains does:
YEAR . MAJOR . MINOR . 0
The first value is the year of release. And the MAJOR resets to 1 each year.
There are additional options like including the alpha/beta/release-candidate letter mark into the version (e.g. 3.5b.123.6897 or 2.3.a), or exotic ones like 3.14159265 (idiosyncratic version in TeX) where developers just add an additional number to the version instead of incrementing it, or 50001 (flag system in BLAG Linux and GNU) where 5 is a major number and 1 is a minor one.
But the main thing that we should think about is how we will compare versions. While it is possible to invent your own schema and convention, it should be possible to say which app version is newer. The version should be comparable. And here we are also bound to how operating systems treat version values. The version is usually included into the application metadata (e.g. the version inside an installer or in a file header). The OS retrieves and uses it to determine if it should allow the user to install an application or not, what component version to reference, etc. Also, almost all OSes allow you to enter only numbers in the version. Below I’ll talk about versions in Windows.
Now then, let’s quickly cover the last type of versioning - codenames. Usually, it is something that could be used instead of or in addition to a version used inside a company or outside by users. For example, Electronic Arts uses the following names for their Battlefield game:
- Battlefield 1942
- Battlefield 2
- Battlefield 2142
- Battlefield 1943
- Battlefield 3
- Battlefield 4
- Battlefield 1
And while we might think that the number is the version - it is actually not! The list above is sorted chronologically by release date. And the version number here is just a codename. Battlefield 1 has number 1 because it is about World War I, not because it is the first version. And 2142 is just some year in the future, since that game has a futuristic setting.
Another example - Windows versions:
- Windows 95 (version 4.0)
- Windows XP (version 5.1)
- Windows Vista (version 6.0)
- Windows 8.1 (version 6.3)
- Windows 10 (version 10.0)
Sometimes developers use codenames internally, for example, as it was with Windows Longhorn. But OK, enough boring theories…
Our own experience of introducing versioning
Now I’m going to go further and talk about what we wanted to achieve in our project, the approach we decided to use and what interesting stuff can be found in Windows and .NET in terms of versioning.
We were not restricted when assigning numbers to a version. Yet, our own criteria for versions are:
- Being lazy like any other .NET developers, we don’t want to change the versions manually and, of course, commit them each time to the repository.
- We don’t have any CI that could set and increase the version for us.
- We want to see the difference between releases, and be able to compare version numbers.
- We want to easily find what developed features does a certain version include.
- And, of course, the version should have values acceptable by Windows and the Windows Installer system (MSI).
A popular option is to include the date into the version: year, month and day. But it could be possible to have few releases per month. So, all three parts of the date should be used.
Version specification in .NET and in Windows
First of all, let’s check System.Version class that represents the version number of an assembly, operating system, or the common language runtime, and look what we can write into each version position. It has the following constructor:
Version(Int32, Int32, Int32, Int32)
However, if we speak about the assembly (or file) version - it’s not true. The VERSIONINFO structure (that is in the header of the files) stores the version as two 32-bit integers, defined by four 16-bit integers. So, the max possible version is FFFF.FFFF.FFFF.FFFF (in hex values). Each part is a WORD, not a DWORD!
OK, clear enough. Let’s try to set the version for a .NET assembly:
[assembly: AssemblyVersion("65535.65535.65535.65535")]
And here we get the second pitfall - the compilation error CS7034:
The specified version string does not conform to the required format - major[.minor[.build[.revision]]]

Looking into MSDN about .NET assemblies we can find a strange restriction:
All components of the version must be integers greater than or equal to zero. Metadata restricts the major, minor, build, and revision components for an assembly to a maximum value of UInt16.MaxValue - 1.
That means that each version value should be from 0 to 65534 (not 65535!) or 0xFFFE (not 0xFFFF!). I’ve asked about it on Stack Overflow and I hope, someday, someone will explain what the max value is reserved for.
Do you think that it is it? No! It is not so simple in Windows...
Version in MSI
Let’s do a small experiment. Since in any case we want to somehow deliver our application to users, we will face questions on how to install it. Let’s create an application and an MSI installer for it (WiX, Advanced Installer, Microsoft Setup Project or any other MSI-based technology).
Now, set the assembly version to 5.0.0.0 and create the installer from it. The product version will be the same - 5.0.0.0. Install it to the system.
In the Windows Registry we can find the following records for our installed application:

Now, set the version to 258.0.0.0. Most likely, you, already understand what I’m trying to check. :) Compile assembly, build the installer and run it over the already-installed version 5.0.0.0. Our new version is definitely greater, however we get an error!

For the version 258.0.0.0, the Registry will contain the following:

It’s an overflow…
Checking the MSI ProductVersion documentation gives us an answer:
The first field is the major version and has a maximum value of 255. The second field is the minor version and has a maximum value of 255. The third field is called the build version or the update version and has a maximum value of 65,535.
But also don’t forget that 65535 can not be used too because of the .NET limitation! Why, Microsoft, why is everything different in your products?...
Also note that MSI doesn’t take into account the fourth part of the version.
The summary of our painful research
Returning to our project… looking at all the described pitfalls, we decided to fill the first three parts with the date. So, the version becomes something like:
17 . 6. 22 . XX (for commit from date 22.06.2017)
Such a version is comparable, sortable, easy to understand and says the date when the last included code change was done.
But on top of that we want to know the exact commit. In case of SVN, it is possible just to include the integer ID. And the version part will fit enough commit numbers. But unfortunately, we have Git with its large hex hash values…
0xFFFF is also forbidden. So, we took only the first three hex letters from the Git hash. Combining it with the known commit date, we can refer to the exact commit for sure. The commit on 22.06.2017 with hash ed8****d3da29cc65ed4c6635c4b186ba4810e71b892 becomes the version:
17 . 6. 22 . 3800 (3800 is a dec representation of ed8).
Such a version is known from Git commit information and can be easily extracted during the build process. We don’t need to commit the version into a repository or do anything manually. We can just set it for the project automatically on the pre-build step and be happy. :) Later, if it’s needed, it’s possible to quickly find the last commit done to the current release.
Conclusion
It is simple. The max possible version of an application in Windows should be:
255 . 255 . 65534 . [65534]
and only the first 3 parts are essential for the OS.
This way you will not face any surprises. As for the value meaning - use whatever suits the project requirements, while it is sortable and comparable. And remember, that while having versions is essential for long-term projects, it also should be convenient to change and track them. I hope our experience will be helpful and save you some time when introducing your own versioning system!




